

Introduction
Dans vos projets personnels ou professionnels, Il vous arrive de faire des traitements sur de gros volumes de données. Le traitement par lots de données est un moyen efficace de traiter de gros volumes de données où celles-ci sont collectées, traitées, puis les résultats par lots sont produits. Le traitement par lots peut être appliqué dans de nombreux cas d'utilisation. Un cas d'utilisation courant du traitement par lots consiste à transformer un grand ensemble de fichiers CSV ou JSON en un format structuré prêt pour un traitement ultérieur.
Dans ce tutoriel, nous allons essayer de voir comment mettre cette architecture en place avec Spring Boot qui est un framework qui facilite le développement d'applications fondées sur Spring.
Qu'est-ce que Spring-Batch?
Spring Batch est un framework open source pour le traitement par lots. Il s'agit d'une solution légère et complète conçue pour permettre le développement d'applications par lots robustes, que l'on trouve souvent dans les systèmes d'entreprise modernes. Son développement est issu d'une collaboration entre SpringSource et Accenture.
Il permet de pallier à des problème récurrents lors de développement de batchs:
- productivité
- gestion de gros volumes de données
- fiabilité
- réinvention de la roue.
N.B: En informatique, un batch est un programme fonctionnant en StandAlone, réalisant un ensemble de traitements sur un volume de données.
Architecture de base de Spring Batch
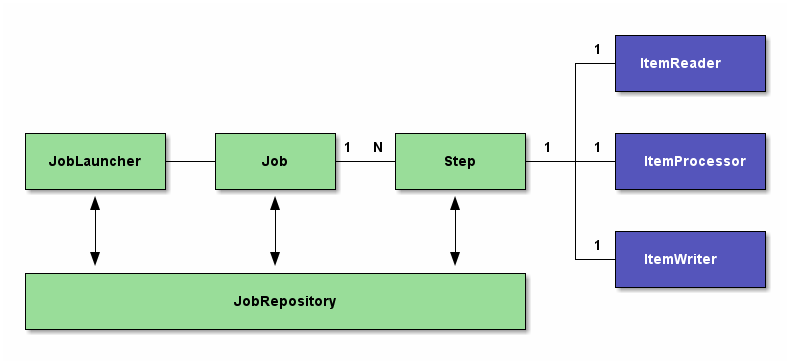
Pour gérer les données d'un batch, on utilise principalement les trois outils suivants:
- Le JobLauncher : il s'agit du composant chargé de lancer/démarrer le programme de traitement par lot (batch). Il peut être configuré pour s'auto déclencher ou pour être déclenché par un évènement extérieur (lancement manuel). Dans le workflow Spring Batch, le JobLauncher est chargé d'exécuter un Job (tâche).
- Le Job : il s'agit du composant qui représente la tâche à qui on délègue la responsabilité du besoin métier traité dans le programme. Il est chargé de lancer de façon séquentielle une ou plusieurs Step.
- La Step : c'est le composant qui enveloppe le cœur même du besoin métier à traiter. Il est chargé de définir trois sous-composants structurés comme suit :
- *- ItemReader** : c'est le composant chargé de lire les données d'entrées à traiter. Elles peuvent provenir de diverses sources (bases de données, fichiers plats (csv, xml, xls, etc.), queue) ;
- ItemProcessor : c'est le composant responsable de la transformation des données lues. C'est en son sein que toutes les règles de gestion sont implémentées ;
- ItemWriter : ce composant sauvegarde les données transformées par le processor dans un ou plusieurs conteneurs désirés (bases de données, fichiers plats (csv, xml, xls, etc.), cloud).
- JobRepository : c'est le composant chargé d'enregistrer les statistiques issues du monitoring sur le JobLauncher, le Job et la (ou les) Step à chaque exécution. Il offre deux techniques possibles pour stocker ces statistiques : le passage par une base de données ou le passage par une Map. Lorsque le stockage des statistiques est fait dans une base de données, et donc persisté de façon durable, cela permet le suivi continuel du Batch dans le temps à l'effet d'analyser les éventuels problèmes en cas d'échec. A contrario lorsque c'est dans une Map, les statistiques persistées seront perdues à la terminaison de chaque instance d'exécution du Batch. Dans tous les cas, il faut configurer l'un ou l'autre obligatoirement.
Pour plus d'informations, je vous conseille de consulter le site de Spring.
Après cette explication bref de l'architecture de spring batch,essayons dès à présent de montrer comment mettre en place un job spring batch qui va lire des données à partir d'un fichier CSV que nous allons par la suite insérer dans une base de données."Let's get into coding".

Configuration du projet
Le moyen le plus simple de générer un projet Spring Boot consiste à utiliser l'outil de démarrage Spring avec les étapes ci-dessous:
- Se rendre sur le site Spring Initializr
- Sélectionner Maven Project et langage Java
- Ajouter Spring Batch, JPA, Lombok, H2 Database
- Entrer le nom du groupe comme "com.example" et l'artefact comme "SpringBatch"
- Cliquez le bouton generate
Une fois le projet généré, il faut le dézipper ensuite l'importer dans votre IDE.
Technologies utilisées:
- JDK 1.8
- Maven
- IntelliJ
- Lombok
- Spring data JPA
- H2 Database
Dépendances du projet
Toutes les dépendances du projet sont dans le fichier pom.xml. Les trois lettres POM sont l'acronyme de Project Object Model. Sa représentation XML est traduite par Maven en une structure de données qui représente le modèle du projet.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.pathus</groupId>
<artifactId>SpringBatchExample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringBatchExample</name>
<description>Demo of spring batch project </description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>Structure du Projet
La structure du projet se présente comme suit:
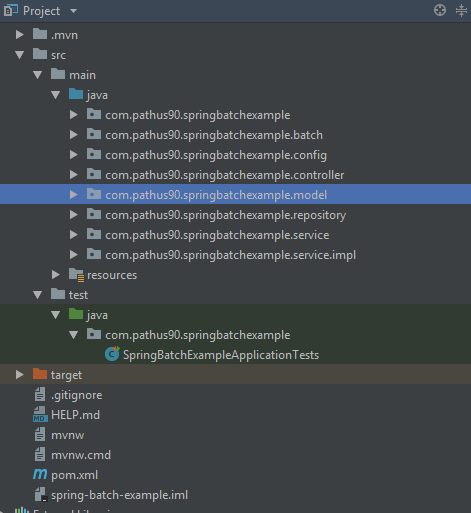
Configuration du Job
Pour activer le traitement par lots, nous devons annoter la classe de configuration avec @EnableBatchProcessing. Nous devons par la suite créer un reader pour lire notre fichier CSV, créer un processor pour traiter les données d'entrée avant d'écrire, créer un writer pour écrire dans la base de données.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import com.pathus90.springbatchexample.batch.StudentProcessor;
import com.pathus90.springbatchexample.batch.StudentWriter;
import com.pathus90.springbatchexample.model.Student;
import com.pathus90.springbatchexample.model.StudentFieldSetMapper;
@Configuration
@EnableBatchProcessing
@EnableScheduling
public class BatchConfig {
private static final String FILE_NAME = "results.csv";
private static final String JOB_NAME = "listStudentsJob";
private static final String STEP_NAME = "processingStep";
private static final String READER_NAME = "studentItemReader";
@Value("${header.names}")
private String names;
@Value("${line.delimiter}")
private String delimiter;
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Step studentStep() {
return stepBuilderFactory.get(STEP_NAME)
.<Student, Student>chunk(5)
.reader(studentItemReader())
.processor(studentItemProcessor())
.writer(studentItemWriter())
.build();
}
@Bean
public Job listStudentsJob(Step step1) {
return jobBuilderFactory.get(JOB_NAME)
.start(step1)
.build();
}
@Bean
public ItemReader<Student> studentItemReader() {
FlatFileItemReader<Student> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource(FILE_NAME));
reader.setName(READER_NAME);
reader.setLinesToSkip(1);
reader.setLineMapper(lineMapper());
return reader;
}
@Bean
public LineMapper<Student> lineMapper() {
final DefaultLineMapper<Student> defaultLineMapper = new DefaultLineMapper<>();
final DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer();
lineTokenizer.setDelimiter(delimiter);
lineTokenizer.setStrict(false);
lineTokenizer.setNames(names.split(delimiter));
final StudentFieldSetMapper fieldSetMapper = new StudentFieldSetMapper();
defaultLineMapper.setLineTokenizer(lineTokenizer);
defaultLineMapper.setFieldSetMapper(fieldSetMapper);
return defaultLineMapper;
}
@Bean
public ItemProcessor<Student, Student> studentItemProcessor() {
return new StudentProcessor();
}
@Bean
public ItemWriter<Student> studentItemWriter() {
return new StudentWriter();
}
}Configuration du job et de la Step
La première méthode définit le job et la seconde définit une seule step. Les jobs sont créés à partir des steps, où chaque step peut impliquer un reader, un processor et un writer. Dans la définition de la step, on définit la quantité de données à écrire à la fois et dans notre cas, il écrit jusqu'à 5 enregistrements à la fois. Ensuite, on configure le reader, le processor et le writer à l'aide des beans injectés précédemment. Quand la définition de notre job, il pourra définir différentes step au sein de notre exécution à travers un ordre précis. la step studentStep sera exécutée par le job listStudentsJob.
@Bean
public Step studentStep() {
return stepBuilderFactory.get(STEP_NAME)
.<Student, Student>chunk(5)
.reader(studentItemReader())
.processor(studentItemProcessor())
.writer(studentItemWriter())
.build();
}
@Bean
public Job listStudentsJob(Step step1) {
return jobBuilderFactory.get(JOB_NAME)
.start(step1)
.build();
}Définition du Reader
Dans la configuration de notre batch, le Reader lit une source de données et est appelé successivement au sein d'une étape et retourne des objets pour lequel il est défini (Student dans notre cas).
@Bean
public ItemReader<Student> studentItemReader() {
FlatFileItemReader<Student> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource(FILE_NAME));
reader.setName(READER_NAME);
reader.setLinesToSkip(1);
reader.setLineMapper(lineMapper());
return reader;
}La classe FlatFileItemReader utilise la classe DefaultLineMapper qui utilise à son tour la classe DelimitedLineTokenizer. Le rôle de DelimitedLineTokenizer est de décomposer chaque ligne dans un objet FieldSet et la propriété names donne le format de l'entête du fichier et permet d'identifier les données de chaque ligne. Cette propriété names est utilisée par la classe d'implantation de transformation de données en objet métier à travers l'objet FieldSet. Il s'agit de la classe indiquée par la propriété fieldSetMapper ( StudentFieldSetMapper).
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
public class StudentFieldSetMapper implements FieldSetMapper<Student> {
@Override
public Student mapFieldSet(FieldSet fieldSet) {
return Student.builder()
.rank(fieldSet.readString(0))
.firstName(fieldSet.readString(1))
.lastName(fieldSet.readString(2))
.center(fieldSet.readString(3))
.pv(fieldSet.readString(4))
.origin(fieldSet.readString(5))
.mention(fieldSet.readString(6))
.build();
}
}
L'interface LineMapper quand à elle est utilisée pour mapper des lignes (chaînes) vers des objets généralement utilisée pour mapper des lignes lues à partir d'un fichier
@Bean
public LineMapper<Student> lineMapper() {
final DefaultLineMapper<Student> defaultLineMapper = new DefaultLineMapper<>();
final DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer();
lineTokenizer.setDelimiter(delimiter);
lineTokenizer.setStrict(false);
lineTokenizer.setNames(names.split(delimiter));
final StudentFieldSetMapper fieldSetMapper = new StudentFieldSetMapper();
defaultLineMapper.setLineTokenizer(lineTokenizer);
defaultLineMapper.setFieldSetMapper(fieldSetMapper);
return defaultLineMapper;
}Definition du Processor
Contrairement à un Reader, les implémentations d'un Processor sont plutôt pour des besoins fonctionnels. Il n'est pas obligatoire et on peut s'en passer si aucun besoin fonctionnel n'est prévu dans notre traitement Dans notre exemple, on a écrit un simple processor qui ne fait que convertir quelques attributs de notre objet student en majuscules et on peut aller au delà de cet exemple avec des cas fonctionnels plus concrets.
import org.springframework.batch.item.ItemProcessor;
import com.pathus90.springbatchexample.model.Student;
public class StudentProcessor implements ItemProcessor<Student, Student> {
@Override
public Student process(Student student) {
student.setFirstName(student.getFirstName().toUpperCase());
student.setLastName(student.getLastName().toUpperCase());
student.setCenter(student.getCenter().toUpperCase());
student.setOrigin(student.getOrigin().toUpperCase());
student.setMention(student.getMention().toUpperCase());
return student;
}
}Definition du Writer
Le Writer écrit les données provenant du processor (ou directement lues par le Reader). Dans notre cas, Il reçoit du processor les objets transformés et chaque objet sera par la suite persisté dans notre base de donnés et transaction sera validée.
import java.util.List;
import org.springframework.batch.item.ItemWriter;
import org.springframework.beans.factory.annotation.Autowired;
import com.pathus90.springbatchexample.model.Student;
import com.pathus90.springbatchexample.service.IStudentService;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class StudentWriter implements ItemWriter<Student> {
@Autowired
private IStudentService studentService;
@Override
public void write(List<? extends Student> students) {
students.stream().forEach(student -> {
log.info("Enregistrement en base de l'objet {}", student);
studentService.insertStudent(student);
});
}
}Fichier de configuration du batch (application.properties)
# Enabling H2 Console
spring.h2.console.enabled=true
# To See H2 Console in Browser:
spring.h2.console.path=/h2-console
spring.h2.console.settings.web-allow-others=true
# ===============================
# DB
# ===============================
spring.datasource.url=jdbc:h2:file:~/test1
spring.datasource.username=sa
spring.datasource.password=
spring.datasource.driver-class-name=org.h2.Driver
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
# ===============================
# JPA / HIBERNATE
# ===============================
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
spring.datasource.continue-on-error=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.H2Dialect
header.names= Rang,Prenoms,Noms,Centre,PV,Origine,Mention
line.delimiter=,
logging.level.org.springframework.web=ERROR
logging.level.com.pathus90=DEBUGFichier CSV à écrire en base de données
Rang,Prenoms,Noms,Centre,PV,Origine,Mention
1,Mamadou Sanou ,diallo,TOMBO 2,1686,MES FLEURS,BIEN
2,SAFIATOU,DIALLO,A.S. TOURE,191,JACQUELINE,BIEN
3,BoubA ,Camara, vh,1686,koumba diawara ,BIEN
4,SAFIATOU,CondE,kk3,1951,kipe,BIENLancement de l'application
Une fois que que avions fini de mettre en place la configuration du batch, regardons dès à present voir si tout ce qui a été dit plus haut fonctionne
Pour exécuter l'application, il faut chercher le fichier qui contient l'annotation @SpringBootApplication qui est le main de notre application.
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling
public class SpringBatchExampleApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBatchExampleApplication.class, args);
}
}Le lancement du main ci-dessus va démarrer notre job et le batch launcher se présente comme suit :
package com.pathus90.springbatchexample;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class BatchLauncher {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job job;
public BatchStatus run() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
JobParameters parameters = new JobParametersBuilder().addLong("time", System.currentTimeMillis()).toJobParameters();
JobExecution jobExecution = jobLauncher.run(job, parameters);
return jobExecution.getStatus();
}
}Un scheduler (planificateur) a été mis en place pour permettre au batch de s'auto déclencher. Dans cet exemple, le batch une fois lancé s'exécuter toutes les 8 secondes. Vous pouvez jouer avec en changeant la valeur fixedDelayen millisecondes.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import lombok.extern.slf4j.Slf4j;
@Component
@Slf4j
public class Scheduler {
@Autowired
private BatchLauncher batchLauncher;
@Scheduled(fixedDelay = 8000)
public void perform() throws Exception {
log.info("Batch programmé pour tourner toutes les 8 secondes");
batchLauncher.run();
}
}En plus d'exécuter le fichier main ci-dessus pour démarrer le batch, on peut également lancé la commande mvn spring-boot:run tout en utilisant une invite de commande.
On peut aussi lancer l'application avec le fichier d'archive JAR et dans ce cas il faut :
Se mettre dans le dossier parent du projet en utilisant une invite de commande et exécuter la commande mvn clean package qui va packager notre projet.
Dans le dossier target, un fichier jar sera crée.
Pour exécuter l'application, utiliser la commande java -jar target/nom_du_fichier_généré-0.0.1-SNAPSHOT.jar
S'assurer aussi que la console H2console a déjà démarré lors du lancement notre application spring batch et la base de données est automatiquement générée ainsi que la creation de la table Student.
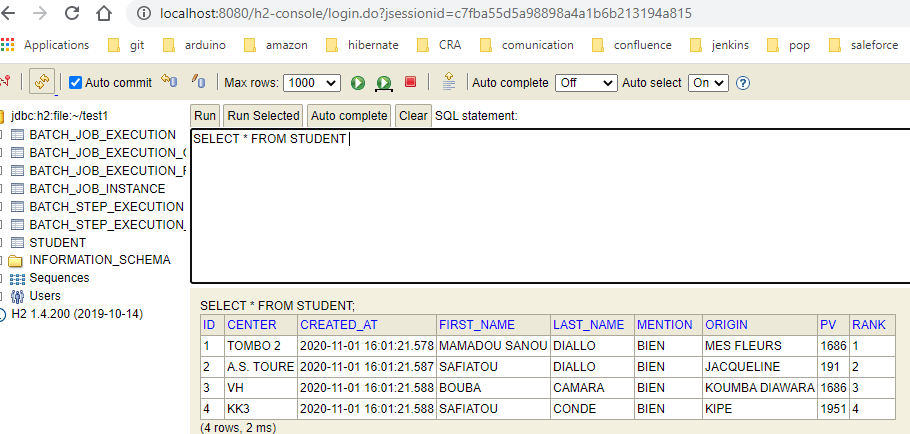
On observe bien que notre fichier a été bien intégré dans notre base de données.
N.B:**Si on souhaite aussi démarrer le batch manuellement sans passer un **schedulerqui va se déclencher en fonction de notre paramétrage , j'ai e xposé une API à l'aide du contrôleur pour appeler le Job Spring Batch.
package com.pathus90.springbatchexample.controller;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.pathus90.springbatchexample.BatchLauncher;
import lombok.extern.slf4j.Slf4j;
@RestController
@RequestMapping("/load")
@Slf4j
public class StudentController {
@Autowired
private BatchLauncher batchLauncher;
@GetMapping
public BatchStatus load() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
log.info("Batch demarré à la demande");
return batchLauncher.run();
}
}il suffit juste de lancer L'URL : http://localhost:8080/load et le batch se lancera
On arrive en fin de notre premier apprentissage sur la programmation des batchs grâce au framework Spring. Laissez des commentaires ou des questions si vous en aviez !
Bonne apprentissage à tous et j'espère que ce premier tutoriel vous sera bénéfique.
Vous trouverez le code source disponible ici


